Overview
What is Training Operator ?
Training Operator is a Kubernetes-native project for fine-tuning and scalable distributed training of machine learning (ML) models created with various ML frameworks such as PyTorch, TensorFlow, XGBoost, and others.
User can integrate other ML libraries such as HuggingFace, DeepSpeed, or Megatron-LM with Training Operator to orchestrate their ML training on Kubernetes.
Training Operator allows you to use Kubernetes workloads to effectively train your large models via Kubernetes Custom Resources APIs or using Training Operator Python SDK.
Training Operator implements centralized Kubernetes controller to orchestrate distributed training jobs.
Users can run High-performance computing (HPC) tasks with Training Operator and MPIJob since it supports running Message Passing Interface (MPI) on Kubernetes which is heavily used for HPC. Training Operator implements V1 API version of MPI Operator. For MPI Operator V2 version, please follow this guide to install MPI Operator V2.
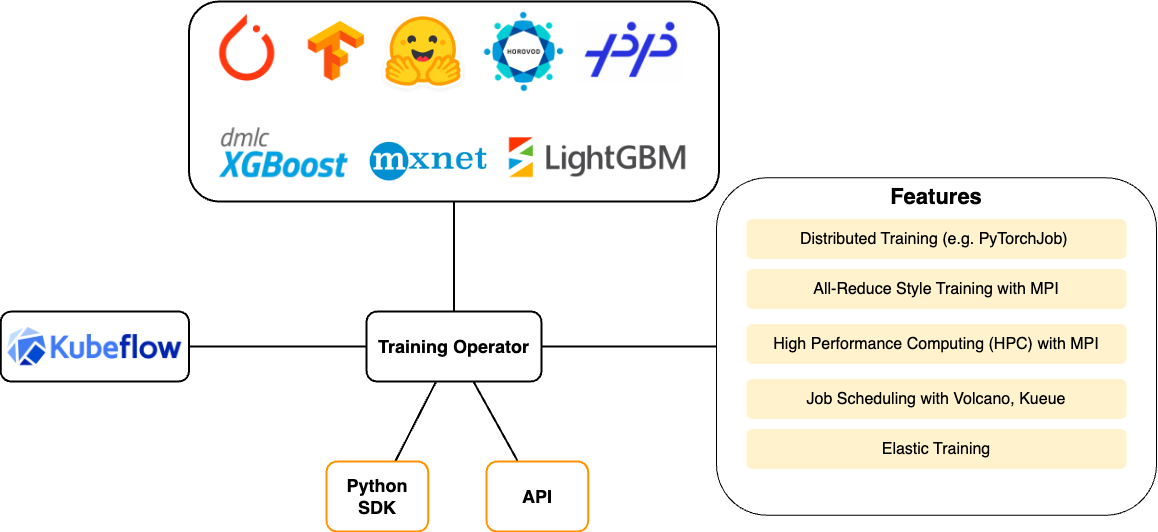
Training Operator is responsible for scheduling the appropriate Kubernetes workloads to implement various distributed training strategies for different ML frameworks.
Why Training Operator ?
Training Operator addresses Model Training and Model Fine-Tuning step in AI/ML lifecycle as shown on that diagram:

- Training Operator simplifies ability to run distributed training and fine-tuning.
Users can easily scale their model training from single machine to large-scale distributed Kubernetes cluster using APIs and interfaces provided by Training Operator.
- Training Operator is extensible and portable.
Users can deploy Training Operator on any cloud where you have Kubernetes cluster and users can integrate their own ML frameworks written in any programming languages with Training Operator.
- Training Operator is integrated with Kubernetes ecosystem.
Users can leverage Kubernetes advanced scheduling techniques such as Kueue, Volcano, and YuniKorn with Training Operator to optimize cost savings for ML training resources.
Custom Resources for ML Frameworks
To perform distributed training Training Operator implements the following Custom Resources for each ML framework:
| ML Framework | Custom Resource |
|---|---|
| PyTorch | PyTorchJob |
| TensorFlow | TFJob |
| XGBoost | XGBoostJob |
| MPI | MPIJob |
| PaddlePaddle | PaddleJob |
Next steps
Follow the installation guide to deploy Training Operator.
Run examples from getting started guide.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.